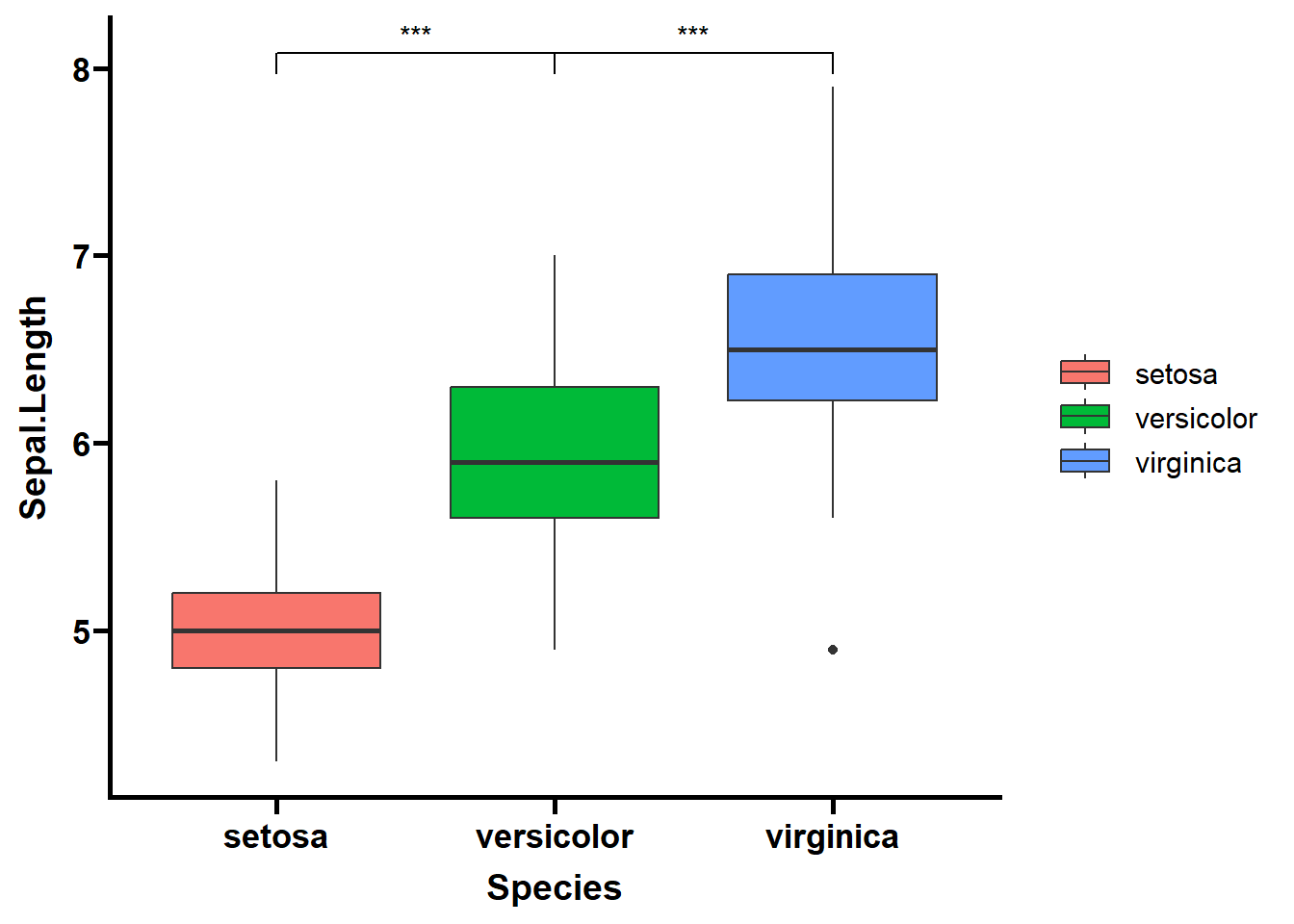
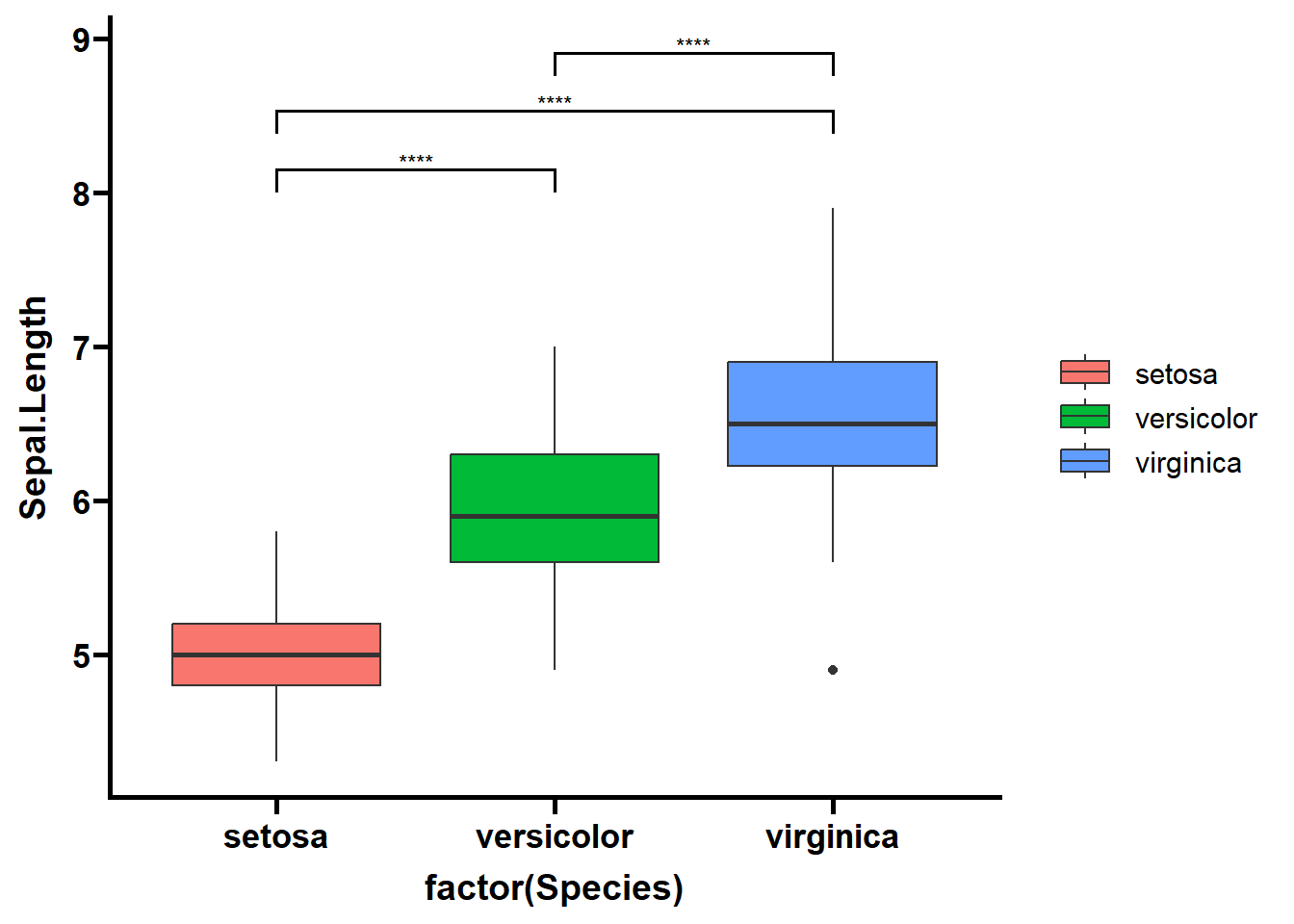
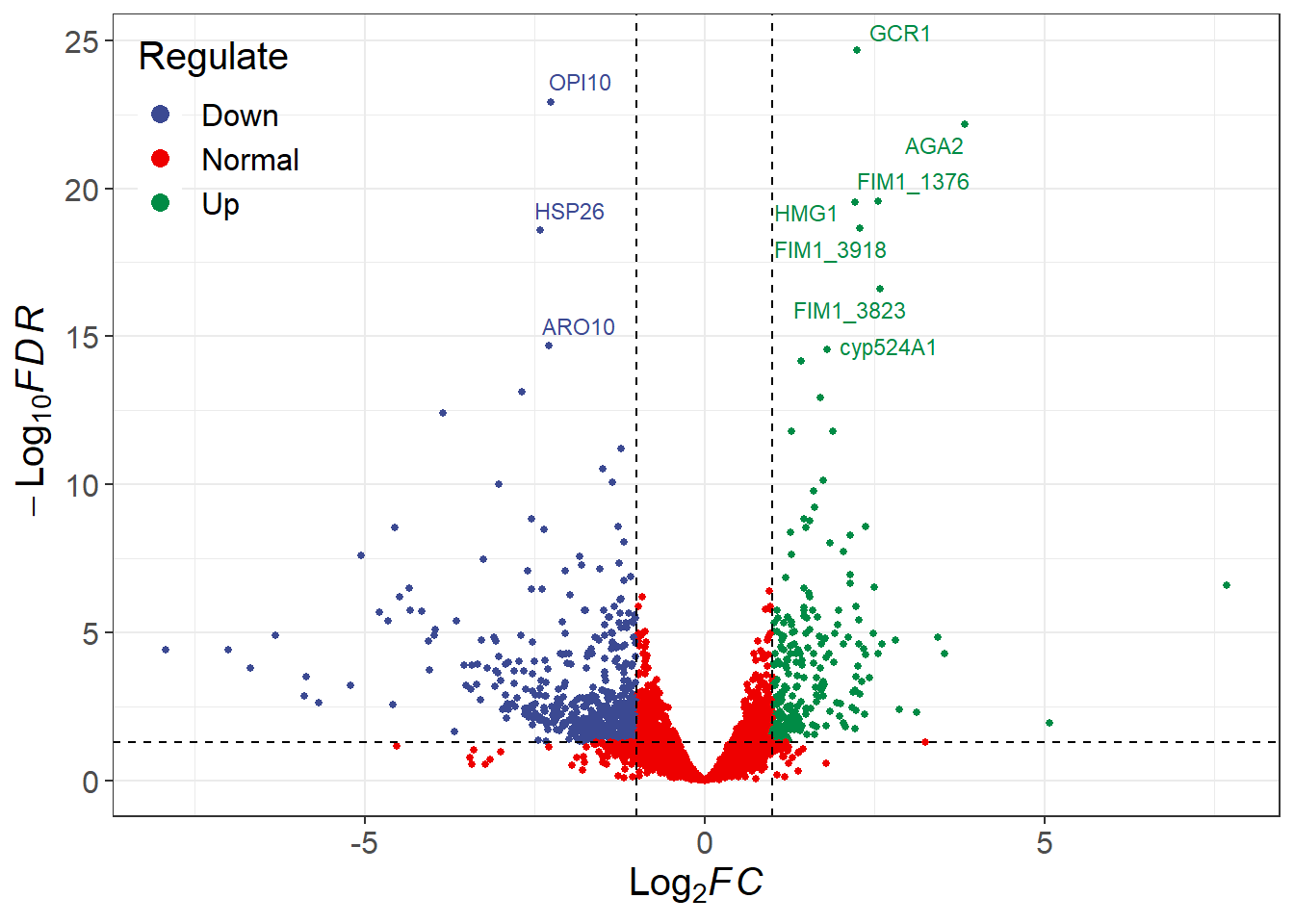
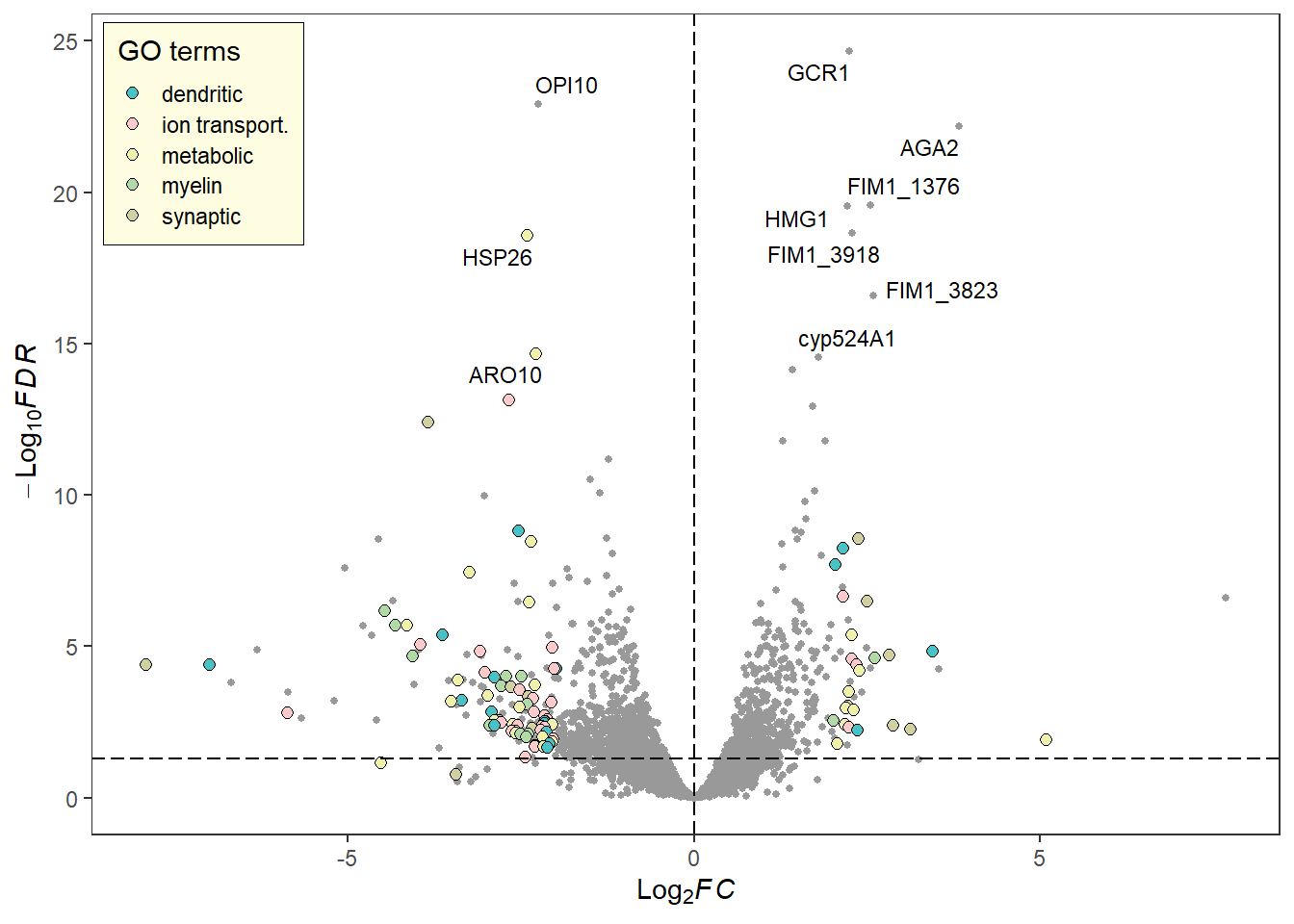
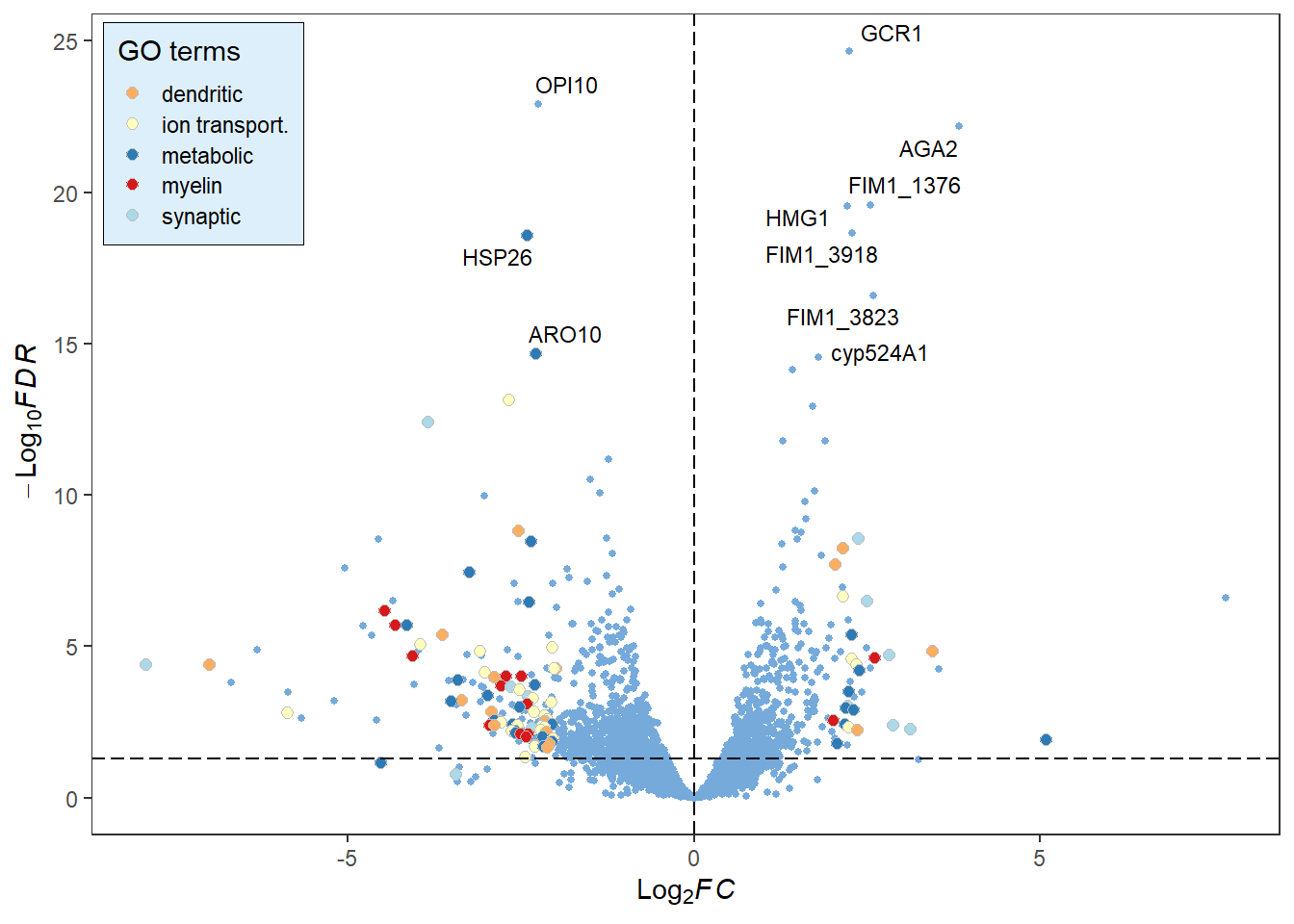
library(RColorBrewer)# Change the fill and color manually:deg_point_fill <-brewer.pal(5, "RdYlBu")names(deg_point_fill) <-unique(term_data$term)term_volcano(data, term_data,x ="log2FoldChange", y ="padj",normal_point_color ="#75aadb",deg_point_fill = deg_point_fill,deg_point_color ="grey",legend_background_fill ="#deeffc",label ="row", label_number =10, output =FALSE)